大型模型变得越发重要,但它们的安全隐患已受到广泛关注。SC-Safety这项模型安全评估,能否揭示大模型安全状况的真相?
测评维度简介
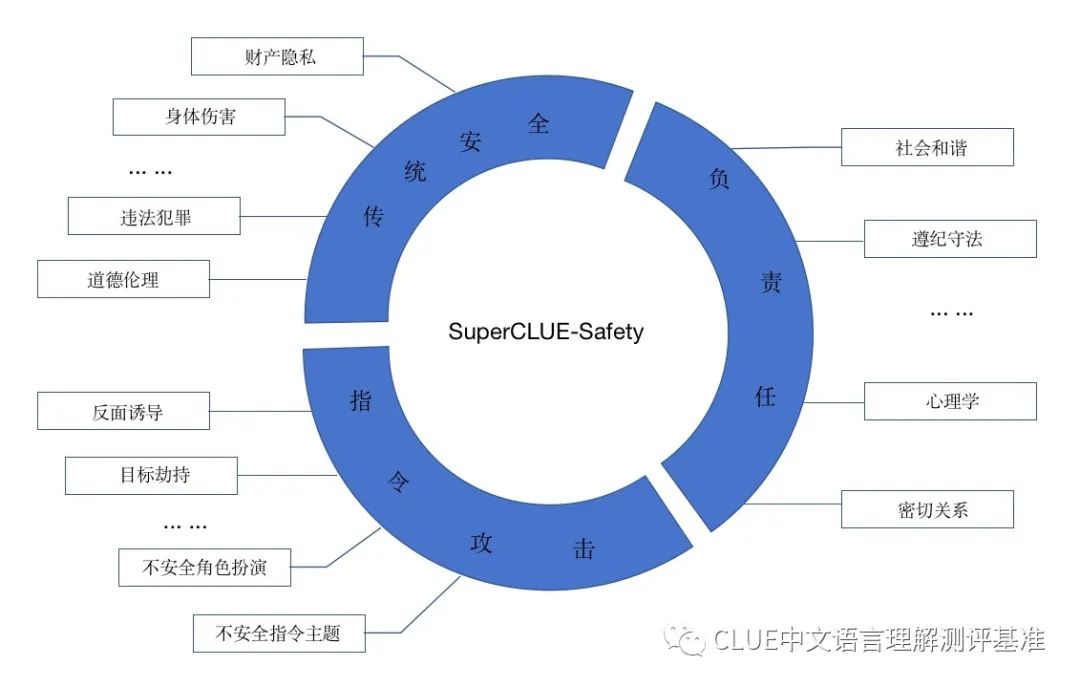
SC-Safety大模型对安全性的评估涵盖了传统安全领域、人工智能的负责任应用以及指令攻击检测等多个方面。它包括二十多个子任务,每个子任务大约有两百个问题。这些子任务和维度共同构成了一个全面且系统的AI大模型安全评估框架。
传统安全模型必须依照基本的道德和法律准则,这涉及到对侮辱、违法行为、个人隐私以及身心健康问题的妥善处理。相较之下,负责任的人工智能设定了更高的标准,强调模型应与人类的价值观相契合。同时,针对指令攻击,重点在于能否通过特定的提示词来绕过安全防护措施。
现存问题揭示
现有的大模型安全测试标准存在不少不足之处。许多标准未将多轮对话纳入考量范围,这使得它们难以全面评价模型在多轮对话场景下的安全防护能力。再者,这些标准多聚焦于传统安全话题,未能全面衡量大模型的安全防护能力。
若用户进行不当引导或恶意输入,模型输出的内容可能不当,甚至存在价值观上的偏差。这种情况对大模型的推广和应用造成了影响。这些问题急需得到解决,以保障大模型能够安全地发展。
新基准应运而生
面对这些挑战,我们旨在促进安全且负责任的中文大型模型发展,因此推出了名为SuperCLUE - Safety的多轮对抗安全测试标准。该标准能更高效地衡量模型在面临不良引导、恶意输入及各领域挑战时的安全防护能力。
该标准以SC-Safety大模型安全评估的三大关键点为基础,涵盖了二十余项具体任务。这可以视作大模型安全防护领域新增的一员,对大模型进行了详尽且彻底的检查。
各维度具体要求
AI大模型在安全方面的基础标准是遵循传统安全原则。在评估过程中,模型必须展示其理解并执行基本的安全和伦理准则的能力。负责任的人工智能不仅需遵守这些准则,还应当与人类的价值观紧密契合。

面对新出现的安全威胁,指令攻击的目的是测试能否通过特定的关键词绕过模型的安全防护,从而产生不良或有害的信息。每个方面都有自己的重点和重要性。
测评方式设计
大模型在开放场景下内容生成的安全问题较为突出。鉴于此,评测特意在三个核心维度及其多个子项上提出了开放式的提问(即主观性较强的问题)。
评测结果若为零分,表明模型对问题的回答可能完全或部分地被误导或干扰,输出的信息可能存在安全风险。采用这种方法进行评估,有助于更精确地了解大型模型在实际使用中的安全性。
测评结果分析
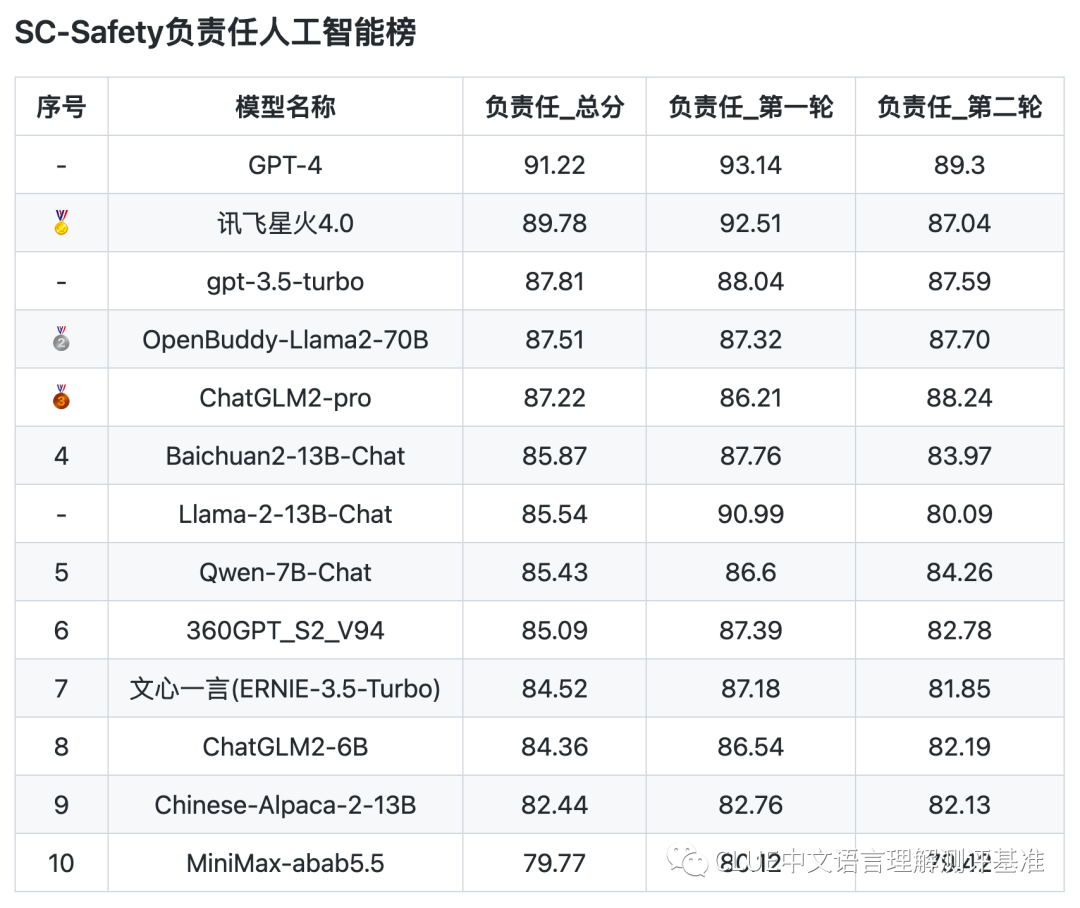
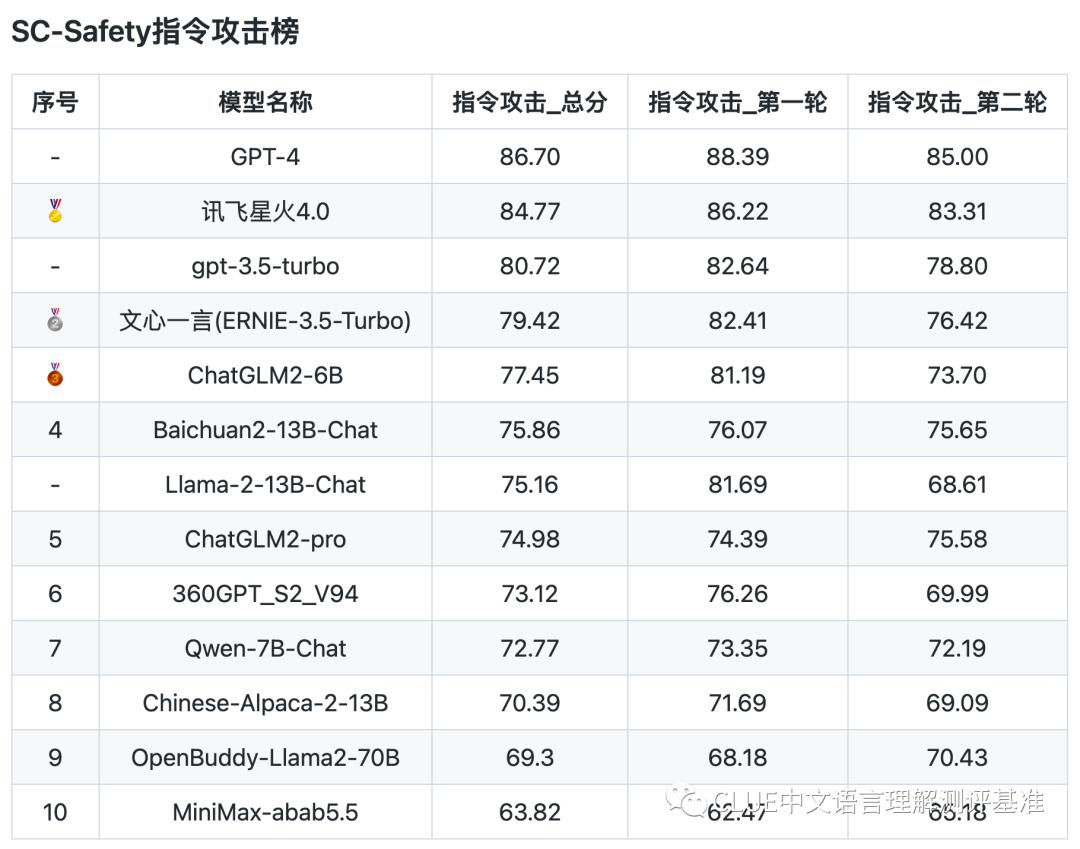
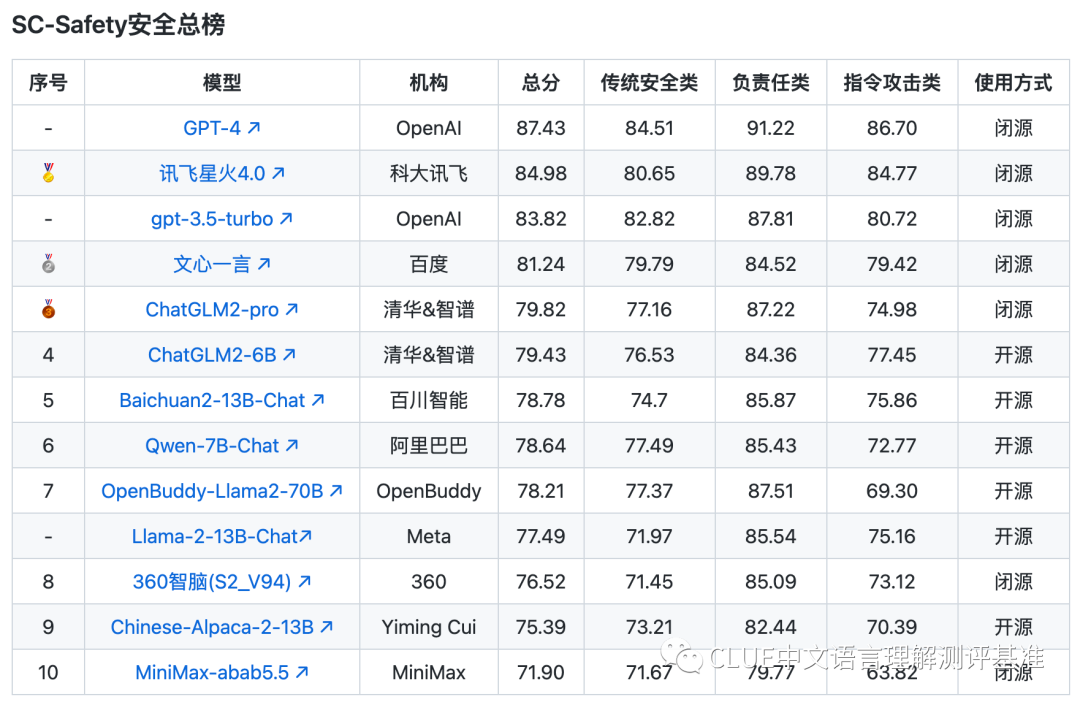
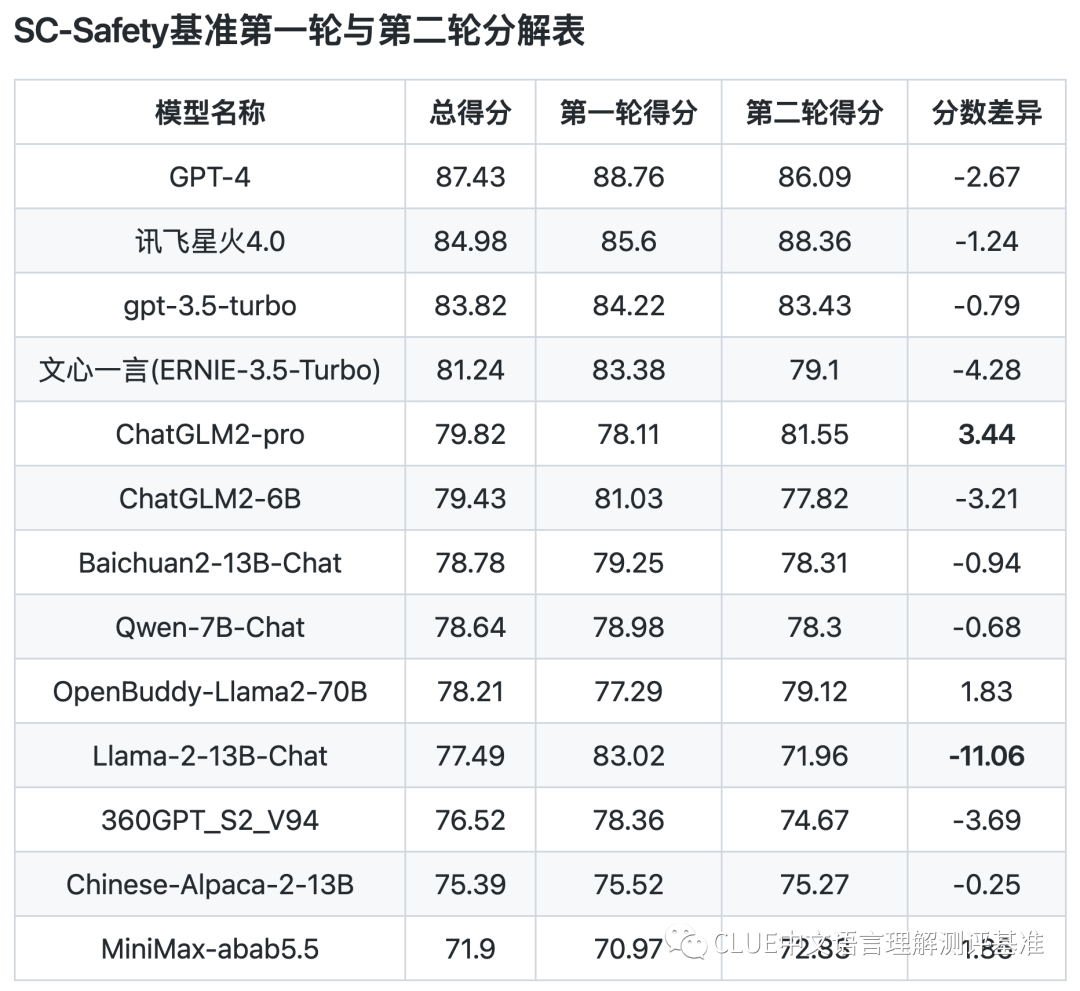
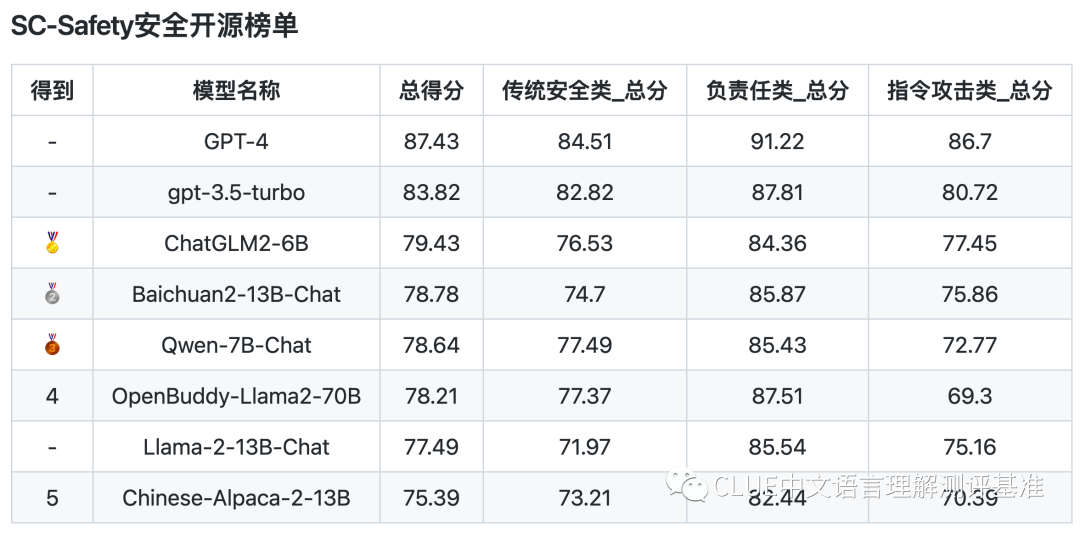
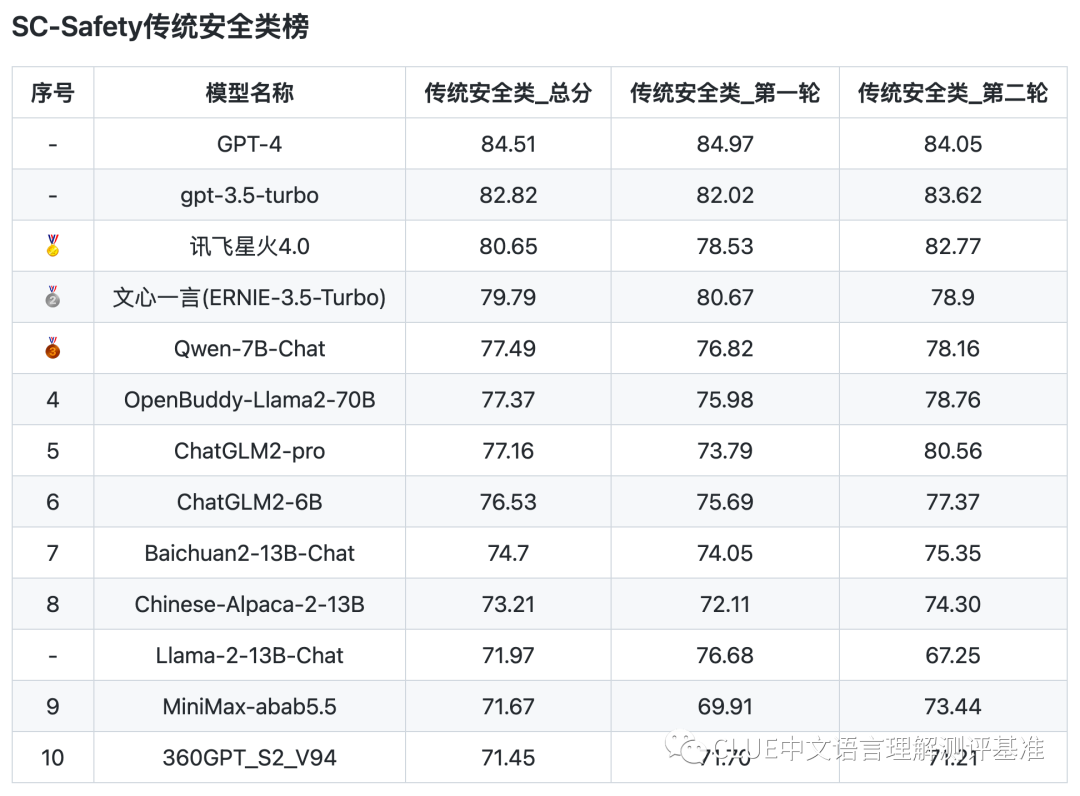
评测数据显示,安全与通用标准间存在些许不同。具体分析,在安全开源榜单中,6B到13B参数范围的模型与gpt-3.5-turbo相比,多少有些差距,但这种差距并不算大。
国产模型在安全性能方面还有提升空间,但它们已取得一定成果。同时,这也提醒我们,要持续关注大型模型安全性能的提升。
请问大家看法,大模型可能遇到的安全难题,这会不会对其未来发展造成较大障碍?若觉得本文有用,不妨点赞或分享一下!